
Have you heard of Andrej Karpathy’s autoresearch project? He has automated the research into training a small LLM with a coding agent. The agent makes changes to improve the training performance, measures the effect, and keeps the changes that work.
That’s cool and we should do it, too. pi-autoresearch is a plugin for the Pi coding agent that implements the autoresearch loop. This means you can easily use it on your own project for whatever numeric targets you might have: benchmark results, build size, compression ratio, …
I already wrote a small experience report about using pi-autoresearch to speed up a compression algorithm. Here’s a quick guide for getting started and another experience report, this time with the Clojure library jsonista.
How to autoresearch
Install Pi and Pi autoresearch. The instructions are on Pi’s homepage and in pi-autoresearch’s repo, but they boil down to:
npm install -g @mariozechner/pi-coding-agent
pi install https://github.com/davebcn87/pi-autoresearch
Connect Pi to a model.
You need to first log in to a model provider or set up a local model.
Start Pi and run /login:
pi
/login
I’ve been using GPT-5.4 medium via a ChatGPT subscription. It’s up to you to choose the best model for your needs.
Create a script that measures the metric that you want to improve. For example, if you’re trying to make a piece of code faster, the script could run a benchmark. Whatever you do, it works best if the script emits only one number and nothing else. If you have multiple benchmarks, you might want to geomean the results. Make note of the unit and whether lower or higher is better.
Create a script to check that the changes didn’t break anything. Okay, you already have this: it’s the command for running your test suite.
Initialize autoresearch.
Use /skill:autoresearch-create to initialize the autoresearch loop.
Depending on the model, it may ask you questions or just figure out something by itself.
You might as well provide the goal right away.
Something like this:
/skill:autoresearch-create Optimize the benchmark suite.
You can run it with `scripts/bench.sh`.
The result is in microseconds - lower is better.
Verify the changes by running `scripts/test.sh`.
This creates a few files, including autoresearch.md which has the instructions for the agent
and autoresearch.sh which runs the measurement command.
It’s worth checking they look reasonable.
If the agent does not start the loop by itself, try /autoresearch.
Enjoy the results.
The agent creates a new branch and commits the changes that it decides to keep.
While it’s running, you press Ctrl-x to see the experiment log.
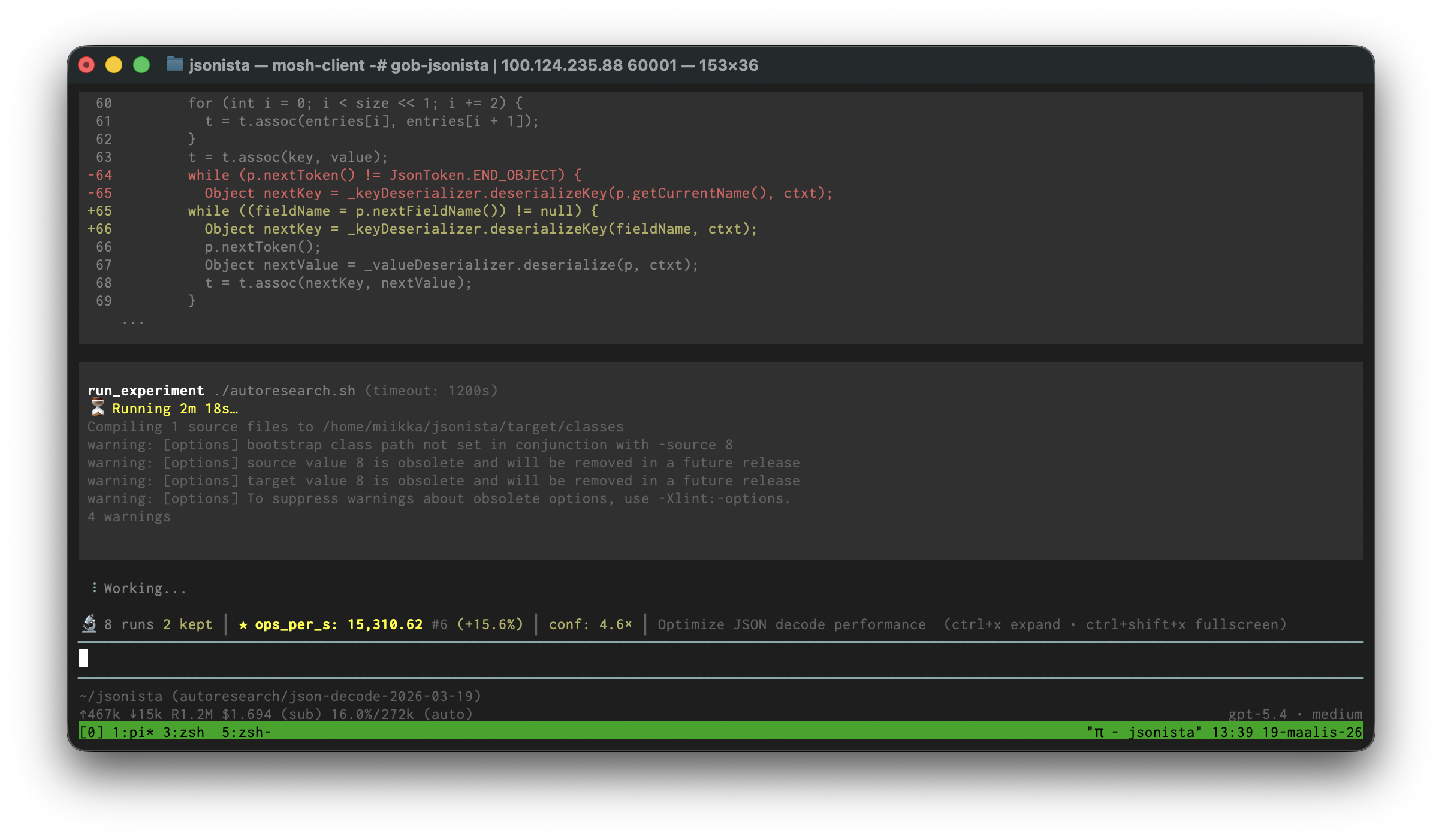
You can stop it once you get bored.
Is it any good?
Jury is still out! It depends on the model! I’ve seen it try out some good ideas, but also do cargo-cult optimizations like replacing math operations with binary operations when the compiler is perfectly capable of doing that. They don’t improve the performance and predictably get discarded.
Back in 2017, I created jsonista, a JSON serialization library for Clojure.1 Its goal was always to be fast, so I thought I’d run autoresearch on it for a bit to see if there are some micro-optimizations left in decoding JSON. To save time, I picked only one benchmark out of the benchmark suite. Ops/sec went up 56%. Here’s the branch I got.
Some of it is reasonable. I cherry-picked the change to use PersistentArrayMap for small maps as a similar approach is used in Clojure core itself.
The agent also tried to special-case the key serialization if the keys are strings. JSON keys can only be strings, so maybe that should be the only case actually. However, checking it by doing a string comparison on the class name is sus:
_stringKeys = keyDeser != null &&
"com.fasterxml.jackson.databind.deser.std.StdKeyDeserializer$StringKD".equals(keyDeser.getClass().getName());
Then there’s code like this (an abridged snippet below). The agent has unrolled the check for duplicate map keys for small maps. It does improve the benchmark result, but jsonista’s benchmark dataset is small. Will it generalize? I don’t know enough about optimizing Java off the top of my head.
switch (size) {
// ...
case 3:
if (!((String) result[0]).equals(result[2])
&& !((String) result[0]).equals(result[4])
&& !((String) result[2]).equals(result[4])) {
return (Map<String, Object>) new PersistentArrayMap(result);
}
break;
case 4:
if (!((String) result[0]).equals(result[2])
&& !((String) result[0]).equals(result[4])
&& !((String) result[0]).equals(result[6])
&& !((String) result[2]).equals(result[4])
&& !((String) result[2]).equals(result[6])
&& !((String) result[4]).equals(result[6])) {
return (Map<String, Object>) new PersistentArrayMap(result);
}
break;
// ...
}
Should you use it?
You need use judgement when applying optimizations to general purpose libraries. Are the optimizations going to generalize? Is the increased code complexity worth it? I’ve tried this approach on two projects and the results have been mixed. The autoresearch loop has found some good ideas but also some changes that sure look like they’re overfitting to the benchmark.
I bet some people will see this and think that it will make their open source library blazing fast without having to understand anything. Those people will be playing stupid games to win stupid prizes.
This could work great for more constrained situations. If you’re looking to, say, optimize the bundle size for your frontend app, this approach could be much more efficient than playing with the bundler settings manually. There are fewer knobs to turn and less things to break.
-
jsonista’s origin story: at that time, I was working at Metosin, a Clojure agency. Tommi Reiman, one of the founders and a prolific open source developer, had an idea for how to make a fast JSON library. I thought Tommi’s idea was stupid and to show him that it won’t work, I started to implement a toy version.
The idea wasn’t easy to implement and I figured I’d make something simpler first to have a baseline. The baseline was faster than Cheshire, the number one JSON library for Clojure, and we decided to ship it. Kalle Lehikoinen packaged it into jsonista. Tommi’s original idea never got implemented and I don’t even remember what it was anymore! ↩︎